

OCR
The OCR (Optical Character Recognition) module provides a way to convert text represented within an image into ASCII text. Once converted it becomes easier to interpret an image by analyzing and processing digital text instead of pixels.The OCR module is meant to be used with short phrases that have been segmented from the background and represented as a black and white image with the 'to-be-extracted' text in white.
To improve performance, the module attempts to reduce false tests on blobs that are not letters, digits, etc. Included in the module are several filters that help to remove non-symbols. These filters are similar to those contained in the Blob Filter module. By eliminating all non-symbol blobs the comparison error between the remaining blobs and the specified fonts can be made larger which will allow more robust recognition.
To provide immediate feedback on which filter is active on a particular blob, each filter will outline a blob that it eliminates. Using this color key, you can quickly adjust the filters to eliminate or preserve a blob for testing against the font charater database.
The final extracted text is placed into an OCR_RESULT variable. Words that are on the same line are separated by a space with words of different lines being separated with a newline character.
Interface
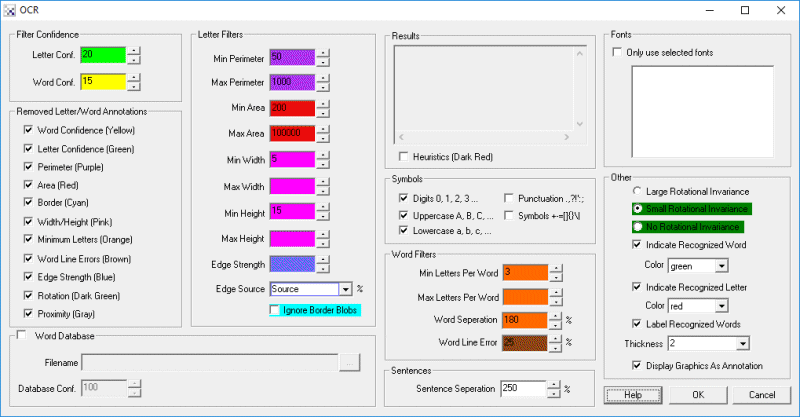
Instructions
1. Letter Confidence - The per symbol confidence threshold. Symbols that are matched to known letters, digits, etc. that fall below this confidence value are not recorded as part of the result. Very low values will include undesirable parts. Making this too high will eliminate letters within words.
2. Word Confidence - The per word confidence threshold. Groups of symbols are combined together into words with their individual confidence values are averaged to create a word confidence.
3. Symbols - Select which groups of characters you want to recognize. Fewer groups will yield faster and more accurate results as less symbols will be compared against the font database.
4. Annotation - To better review what blobs are being removed by which filters you can use the Outline checkboxes to color the blobs that get removed. The colors relate to which filter was used to remove that blob from the final result. The control colors in the configuration screen correspond to the colors of the highlighting used to show the eliminated features. This color code can help to understand why blobs in the image are being removed from consideration.
5. Word Database - To better match against a known list of words you can specify a text file that contains words to be recognized with one word per line. This list will then focus the recognition on a known list instead of determining a best match. Currently the default uses a large English dictionary to help English common words get recognized correctly.
6. Database Confidence - When comparing best matches to the database, the module will replace best matches with secondary, or tertiary, etc. matches. This lowers the overall confidence of the final word. The database matching will stop if this value falls below the specified value to prevent completely wrong matches from being assumed correct when they exist in the database.
7. Min/Max Perimeter - Blobs whose perimeter (the blob's outline) that fall outside of this specified minimum and maximum range will be excluded from recognition.
8. Min/Max Area - Blobs whose area (total number of pixels a blob has) that fall outside of this specified minimum and maximum range will be excluded from recognition.
9. Edge Strength - Blobs whose edge transition is below the specified threshold will be excluded from recognition. The calculation is done by investigating the blob's border transition. Those blobs that are well defined (have a sharp edge) will result in a stronger value.
10. Edge Source - As the image fed into the OCR module is a binary image, using it will not yield the correct results for the edge strength calculation (all blobs have sharp edges). Instead you need to specify the original image that contains the gray values that created the binary image in order to calculate the blob's relative edge strength. This will typically be the Source image.
11. Ignore Border Blobs - Select to remove blobs located on the border of the image that may be mistakenly recognized as incorrect symbols.
12. Minimum Letters Per Word - This specifies how many symbols/letters need to be recognized in order for a word to be recognized. This ensures that multiple symbols are needed in order to create a word. This provides a form of context that helps to isolate and remove incorrect entries.
13. Maximum Letters Per Word - This specifies how many symbols/letters need to be recognized in order for a word to be recognized. This helps to minimize long strings of characters from being identified as a word. 0 indicates that this filter is inactive.
14. Word Separation - In order to determine what makes a word instead of an individual symbol, a separation amount that below which defines a joined symbol and above which defines a new word needs to be specified. The amount is based on a percentage of the previous symbol. For example, if the previous symbol is 30 pixels high and the Word Separation is 125% then any symbol within 38 pixels will be considered part of the same word.
15. Heuristics - When extracting out text from a full scene it is likely that irregular combinations of text are extracted. For example, often in parallel bars (such as those seen in a fence) the module may extract out a word such as "llll". Enabling the heuristics checkbox will check for these irregular matches and remove them from the results. Letters/digits removed using these rules are outlined in dark red to indicate why they have been disqualified from the end results.
Notes
The OCR module uses font images stored in the OCR folder alongside the RoboRealm install folder. These font files are used to compare against blobs located within the current image to determine the appropriate match. These files are 24x48 graphic files which can be managed from the file explorer interface in Windows and edited in any graphic editor. For performance reasons all these files are combined into an OCR/ocr_database.dat file. Should you wish to modify this database, you can delete this file, download the original GIF files and extract them in the OCR folder. Once you make any modifications and restart RoboRealm again, the ocr_database.dat will be regenerated from those files. Please note the fontnames.txt textfile can also be modified in order to specify entirely new font style additions. When restarting, there will be pause while the module recreates the database file. The application will appear frozen during that time.
The OCR module looks for white letters on a black background. So, to quickly correct an image just add a negative module before the OCR module. You may want to segment the letters better so using an Adaptive Threshold module is normally recommended.
Examples
Examples use Adaptive Threshold to segment text from background.
 |  |
 |  |
Variables
OCR_RESULT - The text extracted from the image. OCR_BOUNDING_BOX - Array of integers that specify an index into OCR_RESULT followed by 4 coordinates (2 numbers each) that specify the words bounding box.
See Also
Shape Matching
| New Post |
| OCR Related Forum Posts | Last post | Posts | Views |
 OCR new font
OCR new font
How to add new character/font to the OCR module... |
3 year | 1 | 4576 |
|
convenient way to use TTF fonts
I have a custom font I need to recognize. Is the process to create an individual image (24x48) of each character,... |
4 year | 2 | 1245 |

Hello, i have been trying to compare two codes for a match using and OCR. Is there a way to split the OCR result variable for ea... |
4 year | 3 | 5104 |
|
OCR Help with Similar Characters
In my use case, the characters, 0, Q, 8, S seem to get confused frequently. In another post, I saw a suggestion of using a match... |
6 year | 1 | 1624 |

I was trying to use OCR in a curved text but (7 numbers) and it was only able to read 3 of them. Is there a way to read it all? ... |
8 year | 8 | 4572 |

Does OCR module support this type of numeric font? I cannot read it after threshold and fill module. ... |
8 year | 3 | 3124 |
|
OCR, 1D and 2D codes
can you read all these codes? OCR Code 39 1D Code 93 1D | 8 year | 2 | 3039 |

Help needed to perform OCR on attached image. ... |
9 year | 3 | 3415 |

Hi STeven, Please ignore my previous post as I have some progress these days. | 10 year | 2 | 3060 |
|
DLL & OCR
Hi, we bought a RR Personal software on October 29, 2012. We're not sure how much have been improved over the years. May conside... |
10 year | 2 | 3745 |

Hi Guys, greeting from Argentina. From several days ago I'm trying to work with OCR module, unfort... |
10 year | 3 | 3818 |

Hi STeven, I am successfully using the OCR module to capture anywhere from 5 to 9 numbers (quantity... |
11 year | 4 | 3719 |

STeven, I am not sure that I have understood the concept of OCR database creation and modification ... |
11 year | 9 | 4328 |

Hi, Can someone please send me an example of using the OCR module in roborealm...I tried playing ar... |
12 year | 17 | 3428 |