

HTTP
The HTTP module provides a way for RoboRealm to access web pages in order to post information within RoboRealm into remote websites and to read information contained in pages across the web. This is similar to the HTTP_Read module but allows for customized urls and processing of textural results instead of images as handled by the HTTP_Read.The main interface provides a selection mechanism to specify what variables are to be send given the provided url. This allows you to create a webpage on your website that will receive variables posted to it from RoboRealm.
Note that like other modules the url can be specified as text OR use the [variable] expressions notation to access the contents of a variable for the actual url to use.
Interface
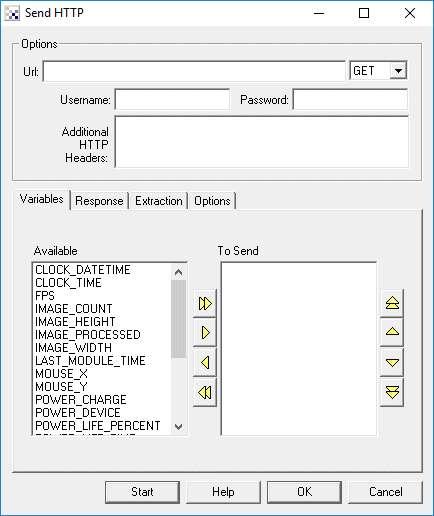
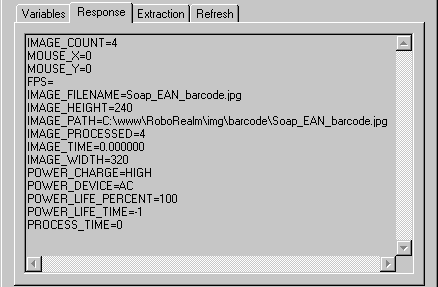
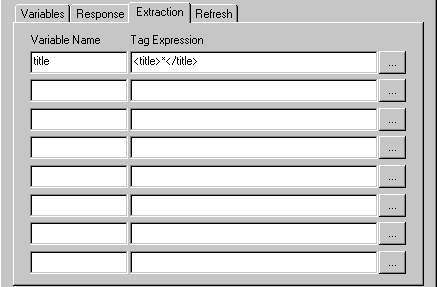
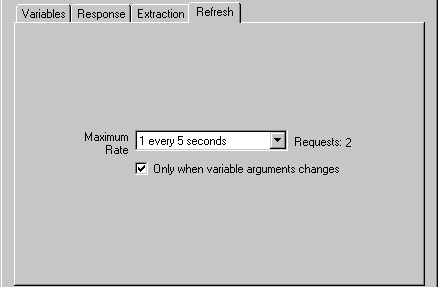
Instructions
1. Url - Specify the url of the webpage that you would like to access. This is the url that you would normally paste into your browser location bar. You can have arguments at the end of the url in addition to specifying variables that would be sent too.
2. GET/POST - Specify what method of request you would like to use. If you are sending large amounts of information you may need to specify POST, otherwise GET should accomplish most tasks.
3. Username / Password - Specify the username/password if HTTP Basic auth is required to gain access to the webpage. Note that this is ONLY used when you see the browser popup its own window requesting for a username and password to gain access. If your website has a HTML login page in order to gain access to the website this username and password will NOT work for that form of login.
4. Additional HTTP Header - You can specify additional HTTP parameters (perhaps for login authorization) that will be sent with the query. This is provided for those advanced users that have a deep understanding of HTTP requests and what information can be provided along with those requests. Note that this module will issue requests as if they came from an IE browser (USER_AGENT).
5. Variables - Select those variables that should be sent to the webpage specified in the URL textbox. All specified variables will be added as CGI parameters and sent to the webpage. Those variables that are arrays will be converted to comma delimited strings and sent as such.
6. Response - After press the Start button the Response text area will show the text returned from the specified url. You can use this tag to investigate the returned text and/or errors that may be returned from the webserver as HTML. The returned text can then also be used as a guide to determine what information should be extracted back into variables for use within RoboRealm.
7. Extraction - As webpages come in various different formats the Extraction tab allows you to create HTML tag expressions that define where within a page is the piece of text to be extracted and placed into a variable. The Variable Name field should be used to specify a variable name that will become a variable within RoboRealm that contains the extracted text. The tag expression is a parsing expression that defines the start and end of the text to be extracted using HTML or XML tags to delineate the target text. For quick access to several examples click on the [...] button and select one of the displayed expressions. See below for more information on allowed formatting and specifications for tag expressions.
8. Options - Specify how frequently you want the request to be made. Note that when viewing a live webcam the rate of pipeline execution can be around 30 frames per second which would mean that 30 HTTP requests could be issued within one second. To lower the load on your webserver you should specify an appropriate request rate. The default is set to restrict requests to at most 1 per second. As an additional requirement you can also select the "Only when variable arguments change" checkbox which will only reissue the HTTP request when at least one of the variables that you specified in the first tab actually change. If nothing changes then no HTTP request is sent which assumes that no new information is present and thus no HTTP request is required. If no variables are being used this checkbox is ignored.
9. Options - Async - If you want to execute a query but not slow down the pipeline and only get the value when it is returned you can select the synchronous execution checkbox. This tells the module to issue the HTTP request but not wait for the answer and instead continue processing. When the request is returned by the remote webserver the information will be added as variables when the module is executed on the next pipeline iteration. This allows you to query slower sites without slowing down the pipeline execution in order to wait for the reply.
10. Start - Press the start button to execute a single request and then wait based on the refresh rate (and changed data) to execute the next. Note that regardless of the refresh rate one HTTP request will execute to allow you to see any errors and possible results to any extraction being performed.
Tag Expression
Tag expressions permit you to isolate a piece of text within the HTML page based on its context within the page. This allows you to perform text extraction on pages not necessarily built to make extraction easy (i.e. the returned text is meant for humans to look at and not as an XML, RSS feed, CSV file, etc). Most text within HTML pages is surrounded by HTML or XML tags that can be used to uniquely identify that text within the page. The tag expression is how you specify that context.
For example, suppose you wanted to extract out the title from a document such as
<html> <head><title>This is a test</title></head> <body>...</body> </html>you could use the tag expression <title>*</title> to extract out "This is a test". The expression basically means look for the title tag, then extract out text (i.e. '*') until you see the end title tag. Thus you use the HTML tags to delineate what text to extract. A couple more examples:
Text: <div class="header">This is a test</div>
Expr: <div class="header">*</div>
Result: Extracts out "This is a test" within a div tag with
the class equal to "header".
Text: <meta name="author" content="Roy Lichenstein">
Expr: <meta name="author" content="*">
Result: extracts out "Roy Lichenstein" or the value of content within an HTML meta tag.
Text: <b>thi<e><r>ffe</r></e>s</b><g>test</g>
Expr: <b>!</b><g>&</g>
Result: Extracts out the word "test" since only text is extracted as specified by '!'
Text: <b>bolded</b>
Expr: <i>*</i>|<b>*</b>
Result: Extracts out "bolded" in either bold or italic tags as specified by the 'or' symbol '|'.
Text: <b><font>hello<font>from</font>world</font></b>
Expr: <font depth=2>*</font>
Result: Extracts out "from" since it is 2 font levels deep (i.e. nested tags).
Text: <b><font>hello<font>from</font>world</font></b>
Expr: <font>#</font>
Result: Extracts out "Hello<font>from</font>world" since the first font tag
triggers the match and the '#' means extract out text and tags.
Text: <b><font>hello<font>from</font>world</font></b>
Expr: <font>*</font>
Result: Extracts out "Hellofromworld" since the first font tag
triggers the match and the '*' means extract out only text and ignore the second level font tags.
Text: <b>From Andy Minors</b>
Expr: <b>From *</b>
Result: Extracts out "Andy Minors" since the bold tag and "From" text all match.
Text: <b>Cost $191.00</b>
Expr: <b>Cost \\$*</b>
Result: Extracts out "191.00" since the bold tags match and the word "Cost" starts the text.
Note the use of \\ to indicate that the '$' is NOT a tag expression character but an actual
literal character in the text. '$' means skip text when no '\\' proceed it in the expression.
Text: <div id="extract">text to be extracted</div>
Expr: <any id="extract">*</any>
Result: Extracts out "text to be extracted" since the div tag matches the 'any' tag
and the ids are the same in the text and the expression.
Text: 1,2,3,4,5,6,7,8
Expr: !,!,!,*,
Result: Extracts out the single letter "4" since the first 3 numbers are ignored using '!' and all the
commas match the text. Note that if the final comma were not present the extracted
text would instead be "4,5,6,7,8".
Specifically the symbols understood by the tag expression parser are as follows
* means record text but skip tags.
# means record text and tags.
! means skip text and tags.
% means skip text but record tags.
$ means skip text only.
& means record text only.
+ means start recording matched tags.
- means stop recording.
Html Tag expressions can also use qualifiers within the tags to further refine the extraction process. The following are valid qualifiers:
depth = X - means the tag needs to be nested X deep in order to match.
index = X - means the X occurrence of the tag will only match.
start = X - means match the tag only after X of those tags has been encountered.
end = X - means stop match after the X matches have been made.
row = X - means match the Xth row within a table tag.
row_start = X - means match starting with the Xth row within a table tag.
row_end = X - means stop matching after the Xth row within a table tag.
column = X - means match only the Xth column within a table tag.
column_start = X - means match starting with the Xth column within a table tag.
column_end = X - means stop matching after the X columns have been matched within a table tag.
To reference any tag with a specific attribute use the tagname 'any'.
Examples
![]() Test Submit - Issues a request to the RoboRealm website at
http://www.roborealm.com/show_variables.php?name=value which
just returns back the variables and values that were submitted by the module. This is a useful
test case just to see that information is flowing over to and back from the website correctly.
Test Submit - Issues a request to the RoboRealm website at
http://www.roborealm.com/show_variables.php?name=value which
just returns back the variables and values that were submitted by the module. This is a useful
test case just to see that information is flowing over to and back from the website correctly.
![]() Stock quote - Queries Yahoo for
stock information. Shows the configuration and extraction information to determine the Open,
Close, High, Low and Change of the IRobot stock. Note that the url includes the
stock ticker symbol of IRBT. You can change that ticker to any other stock you wish
to query. The information returned by the url is a comma delimited CSV file which is
parsed by the extraction tag expressions.
Stock quote - Queries Yahoo for
stock information. Shows the configuration and extraction information to determine the Open,
Close, High, Low and Change of the IRobot stock. Note that the url includes the
stock ticker symbol of IRBT. You can change that ticker to any other stock you wish
to query. The information returned by the url is a comma delimited CSV file which is
parsed by the extraction tag expressions.
![]() Headline News - Queries Yahoo for
the first title of the headline news RSS feed. Note that while an RSS feed is actually
XML the format is the same as HTML and thus the tag expressions work well to extract
out just the required information.
Headline News - Queries Yahoo for
the first title of the headline news RSS feed. Note that while an RSS feed is actually
XML the format is the same as HTML and thus the tag expressions work well to extract
out just the required information.
![]() Weather - Queries Yahoo for
the weather in Sunnyvale California. Have a look at
Yahoo Weather Access
to see what to change the 2502265 code to for your location.
Again, while the information is being passed back as an RSS feed it is
XML and thus the tag expressions work well to extract
out just the required information.
Weather - Queries Yahoo for
the weather in Sunnyvale California. Have a look at
Yahoo Weather Access
to see what to change the 2502265 code to for your location.
Again, while the information is being passed back as an RSS feed it is
XML and thus the tag expressions work well to extract
out just the required information.
![]() Joke - Queries Joke of the Day
and extracts out the joke displayed on that homepage. In this case the information
was not presented in an XML or CSV format but is extracted out from the page
using the class = "quote content".
Joke - Queries Joke of the Day
and extracts out the joke displayed on that homepage. In this case the information
was not presented in an XML or CSV format but is extracted out from the page
using the class = "quote content".
![]() Horoscope - Queries www.astrology.com
website for the horoscope for Aries. Once again a div and a HTML class is
used to isolate just the horoscope text in the page.
Horoscope - Queries www.astrology.com
website for the horoscope for Aries. Once again a div and a HTML class is
used to isolate just the horoscope text in the page.
![]() RoboRealm count - Queries Google
to see how many results there are for the query RoboRealm! Yea, ok, this one is just for us!
RoboRealm count - Queries Google
to see how many results there are for the query RoboRealm! Yea, ok, this one is just for us!
It is important to note that while very versatile the tag expression language does have a fatal flow. If the website owners decide to change the format and tag structure of their website (i.e. a redesign) these text extraction expressions may cease to work. Thus it always makes sense to first look for an RSS, XML or other computer format feed and base the extraction on that as those formats are less likely to change when compared to regular HTML pages.
Variables
HTTP_RESULT - always contains the entire source text returned by executing the HTTP url. X - any variable specified in the Extraction tab.
See Also
HTTP Read
| New Post |
| HTTP Related Forum Posts | Last post | Posts | Views |
|
HTTP module, string variables, JSON parsing...
If one has used the JScript module to create a 6 KB or 8 KB string variable containing JSON data, is it possible to use the HTTP... |
11 year | 5 | 4268 |
|
Not a JPEG error when using read_HTTP module
When using the read_HTTP module to pull an image from a URL generated by EZ-Robots's EZ-Builder software I get a "Return Image... |
12 year | 21 | 4507 |
 HTTP Read module, Image format
HTTP Read module, Image format
Which image formats does the HTTP Read module handle? Roborealm crashes with my custom image server that serves GI... |
15 year | 8 | 4793 |
|
Hello! Thank you for developing such great program, wich gives robotbuilders the huge variety of po... |
15 year | 5 | 8386 |
|
Live Sports Updates
I was wondering how I could get live sports updates using the new HTTP module. I am not sure how to go about doing th... |
16 year | 2 | 5039 |